以下两个方法
1. 修改robots.txt文件:通过FTP或网站主机的文件管理器,找到网站根目录下的robots.txt文件,添加如下规则:
User-agent: *
Disallow: /landing-page//landing-page/ 这个是着陆页的URL,比方说你要禁止这个页面被搜索引擎收录。
https://www.abc.com/products123/
那么代码设置如下:
User-agent: *
Disallow: /products123/这个设置方法是最简单,前提要懂一些代码基础,还有ftp知识。
2. 安装Yoast SEO插件,然后找到这个着陆页,找到高级设置。
具体步骤操作:
- 打开WordPress后台,进入“页面”部分,选择你想要设置的着陆页。(或者模板–着陆页,其实就是找到相对应的页面)
- 在编辑页面的下方,找到Yoast SEO的插件选项。
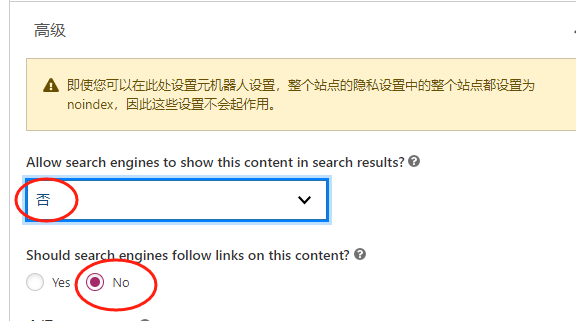
- 在Yoast SEO的“高级”设置中,找到“Allow search engines to show this content in search results?”选项。
- 将这个选项设置为“否”,这样插件就会自动在该页面上添加
noindex的meta标签,告诉搜索引擎不要索引这个页面。
- Allow search engines to show this content in search results?
- 选择“否”,这样就会告诉搜索引擎不要在搜索结果中显示这个页面。
- Should search engines follow links on this content?
- 你可以选择“No”,这样不仅可以防止页面被索引,还可以阻止搜索引擎通过这个页面上的链接爬行到其他页面。
然后点击更新
接着再次回到着陆页的页面,点击查看。就来到这个页面的前端效果了。
比方说这个链接:https://www.abc.com/test2024/
然后右键源代码,我们就会看到前端代码写着noindex。这就说明 这个页面 不会搜索引擎收录了。
<meta name=’robots’ content=’noindex, nofollow’ />

相关说明如下(AI讲解):
<meta name='robots' content='noindex, nofollow' /> 是一个HTML标签,用于告诉搜索引擎的爬虫(也称为机器人或爬虫)关于页面的索引和抓取行为的指令。
这个标签位于网页的<head>部分。下面是这个标签中两个指令的解释:
- noindex:
- 这个指令告诉搜索引擎不要索引这个页面,也就是说,不要将这个页面的内容添加到搜索引擎的数据库中。因此,当用户在搜索引擎中进行搜索时,这个页面不会出现在搜索结果里。
- 使用
noindex通常是因为你不希望某个页面对公众可见,或者该页面是重复内容、低质量内容,或者是为了网站内部使用而不打算被搜索引擎收录。
- nofollow:
- 这个指令告诉搜索引擎不要跟踪(或称“爬行”、“抓取”)页面上的任何出站链接。也就是说,搜索引擎不会通过这个页面上的链接继续访问和索引链接指向的其他页面。
nofollow通常用于防止链接权重被传递到外部网站,或者用于防止爬虫浪费资源去抓取对SEO不重要的页面。
将这两个指令结合使用(noindex, nofollow)是一种常见的做法,用于隐藏页面对搜索引擎,同时防止页面上的链接影响搜索引擎对其他页面的评价。